Category Archives: Nhập môn Toán Tài Chính
Tiếp cận ban đầu trong ước lượng độ đo rủi ro
 Bài viết sau đây sẽ là tiếp nối của chuỗi bài viết về độ đo rủi ro, chúng ta sẽ làm việc với 2 vấn đề cơ bản đó là làm rõ định nghĩa về mặt toán học của độ đo rủi ro trong đó chú trọng vào vấn đề thế nào là một độ đo rủi ro Coherent (có thể tạm dịch là độ đo rủi ro “nhất quán” hoặc “chặt chẽ”) và những giả định quen thuộc xung quanh việc ước tính VaR.
Bài viết sau đây sẽ là tiếp nối của chuỗi bài viết về độ đo rủi ro, chúng ta sẽ làm việc với 2 vấn đề cơ bản đó là làm rõ định nghĩa về mặt toán học của độ đo rủi ro trong đó chú trọng vào vấn đề thế nào là một độ đo rủi ro Coherent (có thể tạm dịch là độ đo rủi ro “nhất quán” hoặc “chặt chẽ”) và những giả định quen thuộc xung quanh việc ước tính VaR.
I, Khái niệm về độ đo rủi ro.
Chúng ta mô hình sự bất định của thị trường Tài chính bởi không gian xác suất 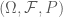
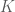
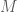

Một độ đo rủi ra được định nghĩa là một ánh xạ từ một tập hợp các biến ngẫu nhiên tới tập các số thực 
Định nghĩa: Ánh xạ 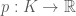
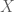

Độ đo rủi ro giúp nhà đầu tư đo lường được mức độ rủi ro mà họ sẽ phải gánh chịu trong thời gian nắm giữ danh mục. Tuy nhiên một độ đo rủi ro như thế nào thì cung cấp cho nhà đầu tư một nguồn có cơ sở hay đáng tin cậy để thực hiện công tác quản trị rủi ro? Dưới đây chúng ta sẽ trình bày về độ đo rủi ro Coherent (độ đo rủi ro nhất quán).
II, Độ đo rủi ro Coherent
Các độ đo rủi ro Coherent (một số tài liệu dịch là các độ đo rủi ro nhất quán hoặc các độ đo rủi ro chặt chẽ) thoả mãn các tính chất sau
a, Bất biến theo phép tịnh tiến (Translation Invariance): Với mọi 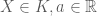

b, Cộng tính dưới (Subadditivity): Với mọi 

c, Thuần nhất dương (Homogeneity): Với mọi 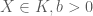

d, Đơn điệu tăng (Monotonicity): Với mọi 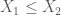

Ý nghĩa của các tính chất này được giải thích như sau:
a, Tính chất bất biến theo phép tính tiến: Với danh mục có độ đo rủi ro 

b, Tính chất cộng tính dưới : Rủi ro của danh mục gồm nhiều yếu tố rủi ro ở đây là 
c, Tính chất thuần nhất dương: Đối với những danh mục có quy mô càng lớn thì độ rủi ro càng cao.
d, Tính chất đơn điệu tăng: Danh mục có mức thua lỗ tiềm ẩn cao thì rủi ro cũng cao.
III, Một số giả định xung quanh việc ước tính VaR:
Thông thường để thiết lập một mô hình Tài chính cần có các giả định đầu vào (input factors), đối với việc tính toán VaR chúng ta cũng cần có những giả định (assumption). Chúng ta sẽ làm quen với một số giả định thông dụng trong các mô hình tính toán VaR tham số, đối với các phương pháp tiếp cận VaR phi tham số sẽ có những đặc điểm khác mà ta sẽ bàn ở các mục sau.
1, Bước ngẫu nhiên
Một biến ngẫu nhiên 

Trong đó 
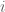
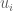
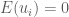
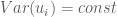
Khi đó theo tính chất của kỳ vọng ta có:
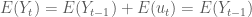
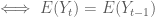


Điều đó có nghĩa là quá trình ngẫu nhiên 
2, Tính dừng: Một chuỗi được gọi là dừng nếu kỳ vọng, phương sai và hiệp phương sai không thay đổi theo thời gian. Điều này có nghĩa là phân phối xác suất của chuỗi là không thay đổi theo thời gian. Có như vậy thì chúng ta mới thực hiện việc dự báo giá trị tương lai của biến ngẫu nhiên dựa trên phân phối xác suất của nó trong một khoảng thời gian nhất định được.
3, Giá trị tài sản không âm: Giá trị của tài sản tài chính, ví dụ như giá chứng khoản, tỷ giá,… được giả sử là không âm (
4, Thời gian cố định: Với giá định này, chúng ta coi rằng điều gì đúng cho một giai đoạn thì cũng đúng cho nhiều giai đoạn khác. Ví dụ như ta xem xét sự đúng đắn trong vòng 1 tuần thì cũng có thể mở rộng thành 1 tháng, hoặc 1 năm,… Chúng ta có công thức mở rộng sau:

Trong đó 
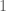
5, Phân phối chuẩn: Phân phối chuẩn (Normal Distribution) nắm giữ 1 vai trò quan trọng trong Tài chính, đây là giả thiết không chỉ của các mô hình phân tích VaR mà còn rất nhiều mô hình khác nữa. Với giả thiết này để ước lượng VaR người ta giả sử rằng chuỗi Tỷ suất sinh lợi của Tài sản tuân theo quy luật phân phối chuẩn, ngoại trừ một số phương pháp tiếp cận VaR phi tham số như mô phỏng Monte Carlo thì giả thiết này không cần thiết. Giả thiết này giúp cho quá trình tính toán VaR trở nên đơn giản hơn thông qua định lý về phân phối chuẩn đa biến, tuy nhiên ngày nay, các chuỗi lợi suất của tài sản Tài chính không phải lúc nào cũng tuân theo phân phối chuẩn và từ đó dẫn đến những ước lượng không chính xác về VaR. Để giải quyết vấn đề về phân phối biên duyên (marginal distribution) của mô hình đa biến thì công cụ Copula trong lý thuyết xác suất-thống kê là 1 sự lựa chọn đang được áp dụng trên thế giới. Vấn đề này sẽ tiếp tục được đề cập trong phần tiếp theo.
Các khái niệm xung quanh Value At Risk
 Đã khá lâu rồi mình không có thời gian cập nhật Blog do một số vấn đề cá nhân. Trong thời gian sắp tới Blog Toán Tài Chính sẽ trình bày một loạt bài viết liên quan tới các độ đo rủi ro trong quản trị rủi ro Tài chính. Những khái niệm như Value At Risk, Expected Shortfall và hàm nối Copula (1 công cụ mới dùng trong việc xác định các độ đo rủi ro nhưng hầu như chưa được phổ biến trong các tài liệu tiếng Việt) sẽ được đề cập theo một cách tiếp cận trực quan, dễ hiểu thay vì các lý thuyết thuần toán học phức tạp.
Đã khá lâu rồi mình không có thời gian cập nhật Blog do một số vấn đề cá nhân. Trong thời gian sắp tới Blog Toán Tài Chính sẽ trình bày một loạt bài viết liên quan tới các độ đo rủi ro trong quản trị rủi ro Tài chính. Những khái niệm như Value At Risk, Expected Shortfall và hàm nối Copula (1 công cụ mới dùng trong việc xác định các độ đo rủi ro nhưng hầu như chưa được phổ biến trong các tài liệu tiếng Việt) sẽ được đề cập theo một cách tiếp cận trực quan, dễ hiểu thay vì các lý thuyết thuần toán học phức tạp.
Chủ đề của bài viết này đó là các khái niệm xung quanh Value At Risk. Với các ứng dụng trong việc tính toán các ngưỡng rủi ro của danh mục đầu tư cũng như tính toán lượng vốn yêu cầu trong hệ thống các tổ chức Tài chính.
I, Tản mạn về Value At Risk
Trong tiêu chuẩn Basel dùng để tính toán các lượng vốn quy định trong hệ thống ngân hàng, khái niệm Value at Risk đã được nhắc tới như là một công cụ được khuyến cáo để tính toán các lượng vốn theo quy định đó. Vậy rốt cuộc Value at Risk là gì? Trong bài viết này, chúng ta sẽ làm quen với các khái niệm cơ bản xung quanh Value At Risk (tạm dịch: giá trị chịu rủi ro, viết tắt: VaR). Trước khi đi vào bản chất toán học của khái niệm này chúng ta sẽ cùng hình dung bằng một số ví dụ sau:
Trong hoạt động của Ngân hàng ngoài các hoạt động cần tới sự lưu động của dòng tiền thì Ngân hàng cũng sẽ phải có một lượng dự trữ vốn nhất định vì nhiều lý do, do pháp luật quy định hoặc với các mục đích khác. Trong các mục đích đó việc dự trữ một lượng vốn để khi có những biến cố bất thường xảy ra chẳng hạn như việc kinh doanh gặp một khoản lỗ lớn khi đó Ngân hàng phải sử dụng số tiền dự trữ để giải quyết hậu quả do biến cố này gây ra. Thực tế, trước khi những độ đo rủi ro được áp dụng tại các Ngân hàng trên thế giới theo tiêu chuẩn Basel thì rất nhiều ngân hàng đã sụp đổ do không có đủ lượng vốn dự trữ cần thiết để chi trả cho khách hàng trong trường hợp họ phải chịu những khoản lỗ khổng lồ do biến động bất thường của thị trường.
Với độ đo rủi ro VaR, ngân hàng sẽ tính toán lượng dữ trữ vốn tối tiểu cần phải trong một mức độ tin cậy cố định (thông thường là 99% hoặc 95%) và trong một khoảng thời gian nhất định (ví dự như 1 ngày, 1 tuần,…) để có thể phòng ngừa những trường hợp xấu gây phá sản sao cho lượng vốn dữ trữ đó là đủ để ngân hàng sử dụng trong trường hợp bất thường xảy ra cũng như không dự trữ quá dư thừa dẫn đến nguồn vốn không thể lưu thông vào hoạt động kinh doanh dẫn đến giảm lợi nhuận. Đây là một ví dụ rất tiêu biểu để minh hoạ cho công dụng của VaR và nó cũng là một vấn đề thời sự thường được biết dưới cái tên “quản trị nguồn vốn kinh tế” (Managing Economic Capital) tập trung chủ yếu vào việc đo lường rủi ro tổng hợp (Risk aggregation) và phân bổ nguồn vốn kinh tế hợp lý (Economic Capital Allocation) .
Ví dụ thứ 2 cũng có phần tương tự ví dụ trên nhưng ở một trường hợp cụ thể hơn. Nhà đầu tư nắm giữ một danh mục chứng khoán đang niêm yết trên sàn HOSE. Ngoài việc tính toán tỷ trọng tối ưu cho rỗ chứng khoán của mình sao cho tối đa hoá lợi nhuận, họ phải xem xét các yếu tố khác như việc với danh mục đó thì khả năng thua lỗ trong 1 ngày là bao nhiêu và họ cần đầu tư như thế nào để nếu rủi ro thua lỗ xảy ra họ vẫn đủ vốn dự trữ để kiểm soát tình hình. Tuy nhiên câu hỏi đặt ra khả năng thua lỗ trong 1 ngày có thể là bao nhiêu? Giả sử số tiền đầu tư là 1 tỷ VND. Nếu nói có thể mất toàn bộ số tiền đầu tư thì ai cũng có thể nói được, đương nhiên điều này hiếm khi xảy ra (nhưng không phải không thể xảy ra!!!). Câu trả lời hợp lý nhất có thể là một con số cụ thể, ví dụ như 250 triệu VDN với độ tin cậy 99%. Đó chính là ví dụ về VaR.
Ứng dụng của VaR không chỉ dừng lại ở đó mà còn nhiều lĩnh vực khác nữa tuy nhiên trong phạm vi bài viết này, chúng ta sẽ tập trung chính vào việc định nghĩa VaR cho danh mục đầu tư gồm các tài sản tài chính quen thuộc ví dụ như cổ phiếu. Đối với những sản phẩm tài chính phức tạp hơn như danh mục kết hợp giữa cổ phiếu và các sản phẩm phái sinh sẽ được đề cập trong các bài viết về sau.
II, Định nghĩa về VaR
Giả sử nhà đầu tư nắm giữ mô hình gồm n cổ phiếu. Đặt 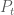
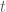

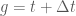
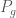
Từ khoảng thời gian từ thời điểm 
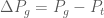


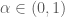

Giá trị 
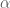
Ta có định nghĩa về VaR như sau: Value At Risk là một thước đo rủi ro thị trường. Nó là một khoản lỗ tối đa mà doanh nghiệp có khả năng gặp phải tương ứng với một mức độ tin cậy và một khoảng thời gian cho trước.
Như vậy VaR của một danh mục tương ứng với chu kỳ 


Có thể hiểu công thức trên một cách trực quan như sau: Ví dụ 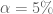
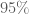


Ví dụ ta tính toán được 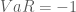

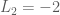
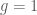

Mặt khác 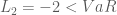


Ta quay lại ví dụ này và xét ở một góc độ tổng quát hơn. Đặt 
Trường hợp 
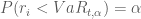
Trường hợp 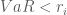

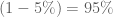


Việc xem xét và biểu diễn dưới dạng xác suất VaR còn tuỳ thuộc vào vai trò của VaR đang thể hiện mức lời lỗ hay là chi phí hoặc là bất kỳ một đại lượng đo lường nào khác… trong trường hợp ta muốn tính chi phí tối thiểu cho một dự án nào đó việc biểu diễn theo công thức xác suất cũng sẽ có thể thay đổi. Vì vậy không nên cố hữu trong suy nghĩ là VaR luôn là một khoản lỗ tối đa hay tối thiểu, là một số âm hay số dương… hãy phân biệt một cách linh hoạt tuỳ từng tình huống.
Ở các bài viết tiếp theo chúng ta sẽ trình bày rõ hơn về các cách tính toán VaR trên một danh mục đầu tư và các giả định của các mô hình đó lường đó.
Định nghĩa về Martingale
Trong bài viết này chúng ta sẽ tìm hiểu định nghĩa liên quan tới lý thuyết Martingale. Từ đó nhắc tới một tính chất quan trọng của chuyển động Brown mà chúng ta đã có dịp làm quen ở các bài viết trước. Mục tiêu của bài viết này chỉ là giới thiệu 1 cách đơn giản và dễ hiểu nhất về khái niệm Martingale cho nên các tính chất của nó không được đề cập nhiều.
Định nghĩa 1: [Martingale] Một quá trình ngẫu nhiên 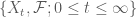


![\displaystyle X_s=E[X_t|\mathcal F_s]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+X_s%3DE%5BX_t%7C%5Cmathcal+F_s%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Với

Khái niệm 

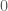
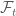

Vậy rốt cuộc ý nghĩa về mặt định tính của Martingale là gì? Ở đây chúng ta làm rõ bằng một ví dụ như sau: khi quan sát một biến ngẫu nhiên
![\displaystyle E[(X_t-X_s)|\mathcal F_s]=0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%28X_t-X_s%29%7C%5Cmathcal+F_s%5D%3D0&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Chúng ta có thể chứng minh điều trên như sau:
![\displaystyle E[(X_t-X_s)|\mathcal F_s]=E[X_t|\mathcal F_s]-E[X_s|\mathcal F_s]=E[X_t|\mathcal F_s]-X_s=X_s-X_s=0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%28X_t-X_s%29%7C%5Cmathcal+F_s%5D%3DE%5BX_t%7C%5Cmathcal+F_s%5D-E%5BX_s%7C%5Cmathcal+F_s%5D%3DE%5BX_t%7C%5Cmathcal+F_s%5D-X_s%3DX_s-X_s%3D0&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Điều quan trọng là Martingale luôn được định nghĩa trên một bộ lọc (một bộ thông tin) và theo một độ đo xác suất nào đó. Dự báo tốt nhất của 


![\displaystyle E[X_t|\mathcal F_s]\ge X_s](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX_t%7C%5Cmathcal+F_s%5D%5Cge+X_s&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle E[X_t|\mathcal F_s]\le X_s](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX_t%7C%5Cmathcal+F_s%5D%5Cle+X_s&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Ví dụ trong thực tế của Martingale có thể kể đến như việc đặt cược một cách công bằng trong các trò chơi bài bạc hoặc quan sát sự biến động của giá cổ phiếu, giá vàng, các bước đi dạo ngẫu nhiên ko có xu hướng (unbiased random walk)…
Nhắc tới Martingale chúng ta cần phải nhắc tới chuyển động Brown. Một trong những tính chất quan trọng của chuyển động Brown chính là tính chất Martingale.
Định lý 1: [Tính chất Martingale của chuyển động Brown]
Với mọi 
![\displaystyle E[W(t)|\mathcal F_s]=W(s)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BW%28t%29%7C%5Cmathcal+F_s%5D%3DW%28s%29&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Hoặc có thể viết lại như sau:
![\displaystyle E[W(t)-W(s)|\mathcal F_s]=0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BW%28t%29-W%28s%29%7C%5Cmathcal+F_s%5D%3D0&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Trong bài viết tiếp theo chúng ta sẽ tìm hiểu về sự biến động ngẫu nhiên của các tài sản tài chính.
Kỳ vọng có điều kiện
Trong bài viết này, chúng ta sẽ làm quen với một vài khái niệm cơ bản trong lý thuyết xác suất mà quan trọng nhất là định nghĩa về kỳ vọng có điều kiện (Conditional Expectation), một trong những định nghĩa và tính chất quan trọng để xây dựng lý thuyết về Martingale. Lưu ý Martingale (Martingale) và PDE (Partial differential equation) là 2 phương pháp tiếp cận để định giá chứng khoán phái sinh phổ biến nhất.
Đầu tiên, chúng ta sẽ tìm hiểu một số khái niệm trong lý thuyết xác suất liên quan tới không gian xác suất (Probability space), lọc (Filtration), kỳ vọng có điều kiện, kỳ vọng có điều kiện cho bởi 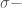

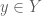
Định nghĩa 1: Ánh xạ 


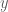

Tập


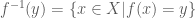



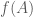

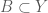


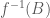
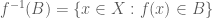
Quay trở lại với lý thuyết xác suất, giả sử có một biến ngẫu nhiên 
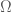
Định nghĩa 2. Cho
1.
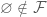
2.

3.

Khi đó cặp 
Không gian mẫu 
Một cách trực quan hơn ta định nghĩa một không gian xác suất là một bộ ba

Một biến ngẫu nhiên 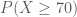
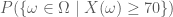

Định nghĩa 3:Cho 

Với
Một lọc
Ở trên chúng ta đã định nghĩa được thế nào là một biến ngẫu nhiên, thế nào là một không gian đo được và thế nào là một lọc cũng như 
Quay trở lại định nghĩa kỳ vọng có điều kiện của X cho bởi Y: 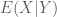

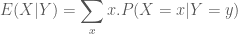
Điều đó có nghĩa là:
Định nghĩa 4: Cho 

1. 

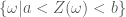
đã chứa trong
2. Với mọi 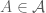
Khi đó ta định nghĩa: 
(The conditional expectation of X with respect to
Trong đó ta định nghĩa hàm số 

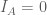
Ta có 
Định nghĩa 5: Giả sử 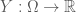
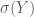

trong đó 
Ta quay trở lại định nghĩa 4, và tìm hiểu xem ý nghĩa của mục 4.2 là gì? Kỳ vọng có điều kiện 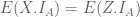
Định lý 1: Cho 

Chứng minh: Ta có thể chứng minh như sau :

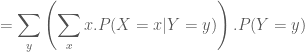
![\displaystyle=\sum_{y}\sum_{x}x.\frac{P[(X=x)\cap (Y=y)]}{P(Y=y)}.P(Y=y)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%3D%5Csum_%7By%7D%5Csum_%7Bx%7Dx.%5Cfrac%7BP%5B%28X%3Dx%29%5Ccap+%28Y%3Dy%29%5D%7D%7BP%28Y%3Dy%29%7D.P%28Y%3Dy%29&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle=\sum_{y}\sum_{x}x.P[(X=x)\cap (Y=y)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%3D%5Csum_%7By%7D%5Csum_%7Bx%7Dx.P%5B%28X%3Dx%29%5Ccap+%28Y%3Dy%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)



Điều này luôn đúng do ta có:
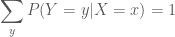
Ngoài ra ta có định lý sau:
Định lý 2. Cho 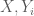

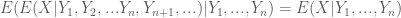

Định lý 3. Cho
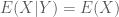
Chứng minh: Trước hết nhắc lại bổ đề:
Bổ đề [Quy tắc nhân của các biến cố độc lập]: Hai biến cố 

Quay trở lại bài toán, từ công thức xác suất có điều kiện và bổ đề ta có:
![\displaystyle P(X=x|Y=y)=\frac{P[(X=x)\cap (Y=y)]}{P(Y=y)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%28X%3Dx%7CY%3Dy%29%3D%5Cfrac%7BP%5B%28X%3Dx%29%5Ccap+%28Y%3Dy%29%5D%7D%7BP%28Y%3Dy%29%7D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)

Mặt khác lại có:
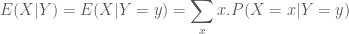

Trong một số trường hợp, khi quan sát các giá trị ngẫu nhiên của biến X từ đó chúng ta muốn dự đoán giá trị của biến ngẫu nhiên thứ 2 là Y. Kỳ hiệu 

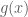

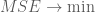

Định lý 4. Cho
![\displaystyle E[\left(Y-g(X)\right)^2]\ge E[\left(Y-E(Y|X)\right)^2]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28Y-g%28X%29%5Cright%29%5E2%5D%5Cge+E%5B%5Cleft%28Y-E%28Y%7CX%29%5Cright%29%5E2%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Đẳng thức xảy ra khi và chỉ khi
Để chứng minh định lý trên ta sử dụng 2 bổ đề sau:
Bổ đề 1: Chứng minh rằng:
![\displaystyle E[\left(Y-g(X)\right)^2]=E[Y^2]-2E[g_0(X).g(X)]+E[g^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28Y-g%28X%29%5Cright%29%5E2%5D%3DE%5BY%5E2%5D-2E%5Bg_0%28X%29.g%28X%29%5D%2BE%5Bg%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Thật vậy khai triển biểu thức ta có:
![\displaystyle E[\left(Y-g(X)\right)^2]=E[Y^2-2Y.g(X)+g^2(X)]=E[Y^2]-2E[Y.g(X)]+E[g^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28Y-g%28X%29%5Cright%29%5E2%5D%3DE%5BY%5E2-2Y.g%28X%29%2Bg%5E2%28X%29%5D%3DE%5BY%5E2%5D-2E%5BY.g%28X%29%5D%2BE%5Bg%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Như vậy để chứng minh bổ đề 1 thì ta chỉ cần chứng minh điều sau là đủ:
![\displaystyle E[Y.g(X)]=E[g_0(X).g(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BY.g%28X%29%5D%3DE%5Bg_0%28X%29.g%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Sử dụng các tính chất của kỳ vọng có điều kiện:
![\displaystyle E[Y.g(X)]=\sum_{x}\sum_{y}Y.g(X).P(X,Y)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BY.g%28X%29%5D%3D%5Csum_%7Bx%7D%5Csum_%7By%7DY.g%28X%29.P%28X%2CY%29&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =\sum_{x}\sum_{y}Y.g(X).\left[P(X).P(Y|X)\right]=\sum_{x}g(X).P(X).\sum_{y}Y.P(Y|X)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D%5Csum_%7Bx%7D%5Csum_%7By%7DY.g%28X%29.%5Cleft%5BP%28X%29.P%28Y%7CX%29%5Cright%5D%3D%5Csum_%7Bx%7Dg%28X%29.P%28X%29.%5Csum_%7By%7DY.P%28Y%7CX%29&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =\sum_{x}P(X).\left(g(X).E[Y|X]\right)=E[g_0(X).g(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D%5Csum_%7Bx%7DP%28X%29.%5Cleft%28g%28X%29.E%5BY%7CX%5D%5Cright%29%3DE%5Bg_0%28X%29.g%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Bổ đề 2: Chứng minh rằng:
![\displaystyle E[\left(Y-g_0(X)\right)^2]=E[Y^2]-E[g_0^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28Y-g_0%28X%29%5Cright%29%5E2%5D%3DE%5BY%5E2%5D-E%5Bg_0%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Dễ thấy:
![\displaystyle E[\left(Y-g_0(X)\right)^2]=E[Y^2-2Y.g_0(X)+g_0^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28Y-g_0%28X%29%5Cright%29%5E2%5D%3DE%5BY%5E2-2Y.g_0%28X%29%2Bg_0%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =E[Y^2]-2E[Y.g_0(X)]+E[g_0^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3DE%5BY%5E2%5D-2E%5BY.g_0%28X%29%5D%2BE%5Bg_0%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Khi đó ta có:
![\displaystyle E[Y.g_0(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BY.g_0%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =\sum_{x}\sum_{y}Y.g_0(X).P(X,Y) =\sum_{x}\sum_{y}Y.g_0(X).\left[P(X).P(Y|X)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D%5Csum_%7Bx%7D%5Csum_%7By%7DY.g_0%28X%29.P%28X%2CY%29+%3D%5Csum_%7Bx%7D%5Csum_%7By%7DY.g_0%28X%29.%5Cleft%5BP%28X%29.P%28Y%7CX%29%5Cright%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =\sum_{x}g_0(X).P(X).\sum_{y}Y.P(Y|X)=\sum_{x}P(X).\left(g_0(X).E[Y|X]\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D%5Csum_%7Bx%7Dg_0%28X%29.P%28X%29.%5Csum_%7By%7DY.P%28Y%7CX%29%3D%5Csum_%7Bx%7DP%28X%29.%5Cleft%28g_0%28X%29.E%5BY%7CX%5D%5Cright%29&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =\sum_{x}P(X).\left(g_0^2(X)\right)= E[g_0^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D%5Csum_%7Bx%7DP%28X%29.%5Cleft%28g_0%5E2%28X%29%5Cright%29%3D+E%5Bg_0%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Từ đó suy ra:
![\displaystyle E[\left(Y-g_0(X)\right)^2]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28Y-g_0%28X%29%5Cright%29%5E2%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =E[Y^2]-2E[g_0^2(X)]+E[g_0^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3DE%5BY%5E2%5D-2E%5Bg_0%5E2%28X%29%5D%2BE%5Bg_0%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =E[Y^2]-E[g_0^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3DE%5BY%5E2%5D-E%5Bg_0%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Quay trở lại định lý 4, dựa vào bổ đề 1 và bổ đề 2 trừ vế theo vế ta có:
![\displaystyle E[\left(Y-g(X)\right)^2]-E[\left(Y-g_0(X)\right)^2]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28Y-g%28X%29%5Cright%29%5E2%5D-E%5B%5Cleft%28Y-g_0%28X%29%5Cright%29%5E2%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =(E[Y^2]-2E[g_0(X).g(X)]+E[g^2(X)])-(E[Y^2]-E[g_0^2(X)])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D%28E%5BY%5E2%5D-2E%5Bg_0%28X%29.g%28X%29%5D%2BE%5Bg%5E2%28X%29%5D%29-%28E%5BY%5E2%5D-E%5Bg_0%5E2%28X%29%5D%29&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =E[g_0^2(X)]-2E[g_0(X).g(X)]+E[g^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3DE%5Bg_0%5E2%28X%29%5D-2E%5Bg_0%28X%29.g%28X%29%5D%2BE%5Bg%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =E[g_0^2(X)-2g_0(X).g(X)+g^2(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3DE%5Bg_0%5E2%28X%29-2g_0%28X%29.g%28X%29%2Bg%5E2%28X%29%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =E\left[(g(X)-g_0(X))^2\right]\ge 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3DE%5Cleft%5B%28g%28X%29-g_0%28X%29%29%5E2%5Cright%5D%5Cge+0&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Ngoài cách chứng minh trên chúng ta có cách chứng minh quen thuộc sau đây:
Cách giải thứ 2:
![\displaystyle E[\left(Y-g(X)\right)^2|X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28Y-g%28X%29%5Cright%29%5E2%7CX%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =E[\left(Y-E[Y|X]+E[Y|X]-g(X)\right)^2|X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3DE%5B%5Cleft%28Y-E%5BY%7CX%5D%2BE%5BY%7CX%5D-g%28X%29%5Cright%29%5E2%7CX%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle =E[\left(Y-E[Y|X]\right)^2|X]+E[\left(E[Y|X]-g(X)\right)^2|X]+2E[\left(Y-E[Y|X]).(E[Y|X]-g(X)\right)|X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3DE%5B%5Cleft%28Y-E%5BY%7CX%5D%5Cright%29%5E2%7CX%5D%2BE%5B%5Cleft%28E%5BY%7CX%5D-g%28X%29%5Cright%29%5E2%7CX%5D%2B2E%5B%5Cleft%28Y-E%5BY%7CX%5D%29.%28E%5BY%7CX%5D-g%28X%29%5Cright%29%7CX%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Ta xem ![\displaystyle E[Y|X]-g(X)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BY%7CX%5D-g%28X%29&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle E[a.Y|X]=a.E[Y|X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5Ba.Y%7CX%5D%3Da.E%5BY%7CX%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle E[\left((Y-E[Y|X]).(E[Y|X]-g(X)\right)|X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28%28Y-E%5BY%7CX%5D%29.%28E%5BY%7CX%5D-g%28X%29%5Cright%29%7CX%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle \left\{E[Y|X]-g(X)\right\}.E[\left(Y-E[Y|X]\right)|X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5C%7BE%5BY%7CX%5D-g%28X%29%5Cright%5C%7D.E%5B%5Cleft%28Y-E%5BY%7CX%5D%5Cright%29%7CX%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle \left\{E[Y|X]-g(X)\right\}.\left(E[Y|X]-E[Y|X]\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5C%7BE%5BY%7CX%5D-g%28X%29%5Cright%5C%7D.%5Cleft%28E%5BY%7CX%5D-E%5BY%7CX%5D%5Cright%29&bg=ffffff&fg=4e4e4e&s=0&c=20201002)

Từ đó ta có:
![\displaystyle E[\left(Y-g(X)\right)^2|X]\ge E[\left(Y-E[Y|X]\right)^2|X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cleft%28Y-g%28X%29%5Cright%29%5E2%7CX%5D%5Cge+E%5B%5Cleft%28Y-E%5BY%7CX%5D%5Cright%29%5E2%7CX%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Suy ra:
![\displaystyle E[VT]\ge E[VP]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BVT%5D%5Cge+E%5BVP%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle \Leftrightarrow E[\left(Y-g(X)\right)^2]\ge E[\left(Y-E(Y|X)\right)^2]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CLeftrightarrow+E%5B%5Cleft%28Y-g%28X%29%5Cright%29%5E2%5D%5Cge+E%5B%5Cleft%28Y-E%28Y%7CX%29%5Cright%29%5E2%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
Đẳng thức xảy ra khi và chỉ khi
So sánh lãi đơn và lãi kép
 I, Đặt vấn đề
I, Đặt vấn đề
Hầu như bất kỳ một sinh viên nào (ít nhất thuộc khối ngành kinh tế) đều đã từng được làm quen với khái niệm lãi đơn và lãi kép.Hiểu đơn giản đó là giả sử ta gửi tiết kiệm 1,000$ vào ngân hàng vào ngày hôm nay, đến khi ta rút số tiền đó ra thì hẳn nhiên sẽ là một số tiền lớn hơn 1,000$ ban đầu bao gồm tiền gốc 1,000$ và lãi từ 1,000$ đô đó. (phần lãi này có thể hiểu nôm na, xem như là chi phí cơ hội hoặc cũng có thể coi là chi phí sử dụng vốn mà ngân hàng trả cho chúng ta, ở đây chúng ta đang trong vai trò người đầu tư, người cho vay và ngân hàng là người đi vay – mục đích là huy động vốn, họ sẽ dùng số tiền đó để tái đầu tư và thu lại được một khoản lợi nhuận khác… Tương tự trong các tình huống khác, chứ không nhất thiết là gửi tiết kiệm).
Khái niệm lãi đơn hiểu đơn giản là phần lãi sẽ chỉ tính từ vốn gốc ban đầu, trong khi lãi kép cứ sau mỗi một kỳ sẽ được cộng dồn phần lãi với phần gốc rồi tính lãi dựa trên phần tính lãi mới đó. Câu hỏi đặt ra là ta nên tính theo loại lãi nào để thu được lợi ích lớn nhất? ( Mặc dù trong thực tế lãi kép được sử dụng phổ biến chứ không phải là lãi đơn)
Chúng ta sẽ xem xét mối quan hệ giữa lãi đơn và lãi kép trong ngắn hạn cũng như dài hạn trong bài viết này để làm rõ đối với mức thời gian đáo hạn nào thì sử dụng loại lãi nào sẽ mang lại lớn ích lớn hơn. Mặc dù đây không phải là một tính chất quan trọng của Toán Tài Chính (quan trọng ở đây được hiểu theo nghĩa là nó có những ứng dụng đáng kể trong lĩnh vực này) nhưng nó là một tính chất rất cơ bản mà người học nhập môn TTC nên biết. Đây cũng là lời giải của mình cho một bài tập trên lớp, môn Toán Tài Chính 1 – Đại học Kinh tế Tp HCM.
Trước hết ta nhắc lại công thức tính của 2 loại lãi suất này.
Công thức tính lãi đơn như sau:
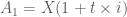
Công thức tính lãi kép như sau:

Trong đó:
-
-
Các biến này có miền xác định như sau: 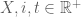

Câu hỏi đặt ra là giá trị của 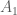

II. Một số lời giải
Ta xét hai khoảng thời gian để so sánh 
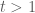




Cố định biến 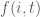

Ta xét hai trường hợp sau:

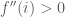


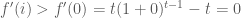
Từ đó suy ra 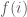
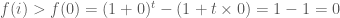
Vậy trong trường hợp này:
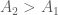



Từ đó suy ra

Vậy trong trường hợp này:
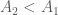
Ngoài cách sử dụng đạo hàm ta có thể sử dụng Định lý giá trị trung bình Lagrange để giải như sau:
Định lý giá trị trung bình
Cho ![\displaystyle f:[a,b]\to \mathbb{R}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f%3A%5Ba%2Cb%5D%5Cto+%5Cmathbb%7BR%7D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
![\displaystyle [a,b]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ba%2Cb%5D&bg=ffffff&fg=4e4e4e&s=0&c=20201002)
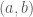

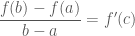
Quay trở lại bài toán: Ta xét hàm 
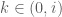
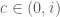

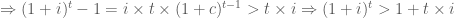
Điều trên đúng là do với 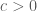

Hiển nhiên đúng do hàm logarit nêpe 
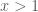
Trường hợp
III. Kết luận:
Như vậy trong ngắn hạn nếu sử dụng lãi suất đơn thì khoản tiền đầu tư sẽ sinh lời nhiều hơn (so với dùng lãi kép) còn trong dài hạn thì sử dụng lãi suất kép thì khoản tiền đầu tư sẽ sinh lời nhiều hơn (so với dùng lãi đơn).
Chuyển động Brown trong Toán Tài Chính
 Trong các bài viết trước chúng ta đã tìm hiểu sơ qua về các khái niệm rất cơ bản liên quan tới giá trị theo thời gian của tiền tệ. Đây là những khái niệm hết sức căn bản nhưng cần thiết để có thể đọc hiểu một quyển Toán Tài Chính. Tiếp tục loạt bài viết này hôm nay chúng ta sẽ nói về một chủ đề rất quan trọng trong nhập môn Toán Tài Chính đó là “Chuyển động Brown và giải tích ngẫu nhiên”. Tất nhiên không thể nào trình bày một cách đầy đủ và bao quát hết được vì đây là 1 lĩnh vực khó, trừu tượng và thậm chí nó là 1 trong những bộ môn được nghiên cứu riêng (Brownian Motion Calculus) và áp dụng khá nhiều trong các lĩnh vực khác như Sinh học, Vật lý… (bản thân mình viết bài này cũng đang tìm hiểu và muốn chia sẽ về một số điều mình rút ra được khi tìm hiểu về nó). Trong bài viết này chúng ta sẽ đề cập một số khái niệm căn bản về chuyển động Brown liên quan tới thị trường Tài chính với một cách hiểu đơn giản nhất mà không quá nặng về mặt toán học (thực tế cho thấy rằng rất nhiều tài liệu viết về chủ đề này nhưng đa phần đều được trình bày dưới các định nghĩa toán học chặt chẽ và cũng không dễ để hiểu). Trước hết chúng ta xem lại một bài viết liên quan đến chủ đề này mang tính lịch sử và định tính sau đó chúng ta sẽ chuyển qua đến lý thuyết Toán học của nó:
Trong các bài viết trước chúng ta đã tìm hiểu sơ qua về các khái niệm rất cơ bản liên quan tới giá trị theo thời gian của tiền tệ. Đây là những khái niệm hết sức căn bản nhưng cần thiết để có thể đọc hiểu một quyển Toán Tài Chính. Tiếp tục loạt bài viết này hôm nay chúng ta sẽ nói về một chủ đề rất quan trọng trong nhập môn Toán Tài Chính đó là “Chuyển động Brown và giải tích ngẫu nhiên”. Tất nhiên không thể nào trình bày một cách đầy đủ và bao quát hết được vì đây là 1 lĩnh vực khó, trừu tượng và thậm chí nó là 1 trong những bộ môn được nghiên cứu riêng (Brownian Motion Calculus) và áp dụng khá nhiều trong các lĩnh vực khác như Sinh học, Vật lý… (bản thân mình viết bài này cũng đang tìm hiểu và muốn chia sẽ về một số điều mình rút ra được khi tìm hiểu về nó). Trong bài viết này chúng ta sẽ đề cập một số khái niệm căn bản về chuyển động Brown liên quan tới thị trường Tài chính với một cách hiểu đơn giản nhất mà không quá nặng về mặt toán học (thực tế cho thấy rằng rất nhiều tài liệu viết về chủ đề này nhưng đa phần đều được trình bày dưới các định nghĩa toán học chặt chẽ và cũng không dễ để hiểu). Trước hết chúng ta xem lại một bài viết liên quan đến chủ đề này mang tính lịch sử và định tính sau đó chúng ta sẽ chuyển qua đến lý thuyết Toán học của nó:
Chuyển động Brown và thị trường chứng khoán http://tiasang.com.vn/Default.aspx?tabid=62&News=1689&CategoryID=7
Trích kết luận của bài viết này: Những áp dụng của lý thuyết ngẫu nhiên này thực sự là rất sâu và rộng. Trong lĩnh vực kinh tế, các biến cố ngẫu nhiên có tác dụng thúc đẩy sự đổi mới. Nếu chúng ta biết được chính xác điều gì sẽ đến thì chúng ta chả cần phải học hành hay nghiên cứu gì nữa. Ở đây không có gì đảm bảo chúng ta sẽ thắng lớn trong một vụ buôn cổ phiếu nhờ vào hiểu biết về chuyển động Brown, bởi vì nó chỉ đơn giản là đem lại cho chúng ta một cách tiếp cận dễ hiểu về sự vận động của các thị trường chứng khoán. Tuy nhiên, dù sao thì lý thuyết về chuyển động Brown cũng giúp chúng ta kiếm tiền dễ hơn và có khả năng tốt hơn trong việc phát triển các chiến thuật đầu tư cũng như đánh giá rủi ro.
I, Quá trình Markov
Trước khi đi vào tìm hiểu về chuyển động Brown chúng ta làm quen với khái niệm quá trình Markov (Markov process). Quá trình Markov là một trường hợp riêng trong các quá trình ngẫu nhiên, quá trình này là một quá trình tại đó giá trị hiện tại (present value) của một biến liên quan tới việc dự đoán giá trị tương lai (relevant) trong khi đó các số liệu quá khứ của biến đó thì không hề liên quan (irrelevant).
Đây là cách giải thích mang tính chất định tính nhiều hơn, chúng ta sẽ không bàn nhiều về định nghĩa toán học của nó mà chỉ cần hiểu được bản chất cơ bản của nó trong bài viết này.
Ví dụ giá chứng khoán thường được giả sử là tuân theo quá trình Markov. Điều đó có nghĩa là nếu giá chứng khoán ACB ngày hôm nay là 100$ thì nếu giá của chứng khoán này tuân theo quá trình Markov thì những dự đoán của chúng ta về giá trị tương lai của chứng khoán này không bị ảnh hưởng bởi giá chứng khoán ACB cách đây 1 tuần, 1 tháng hoặc 1 năm… Giá mà chúng ta cần quan tâm chính là giá hiện tại 100$ mà thôi. Điều này cho thấy một sự trái ngược trong một mặt nào đó vì thông thường nhiều người tiến hành dự báo giá chứng khoán dựa vào số liệu chuỗi thời gian, ví dụ như phương pháp ARIMA chẳng hạn?!
Tuy nhiên các tính chất thống kê của giá chứng khoán ACB trong quá khứ có thể vẫn sẽ hữu dụng trong việc xác định quá trình ngẫu nhiên của giá chứng khoán (ví dụ như để xác định Volatility – độ giao động)…
Quay lại với quá trình Markov. Chúng ta xem xét một biến số tuân theo quá trình ngẫu nhiên Markov. Giả sử rằng giá trị hiện tại của biến số đó là 10 và sự thay đổi trong giá trị của biến số đó trong suốt 1 năm tuân theo phân phối chuẩn 
Sự thay đổi giá trị trong vòng 2 năm là tổng của hai phân phối chuẩn mà mỗi phân phối là

Tiếp tục xem xét sự thay đổi của biến số này trong vòng 6 tháng. Cùng với lập luận như ở trên. Sự thay đổi trong vòng 1 năm tương ứng với sự thay đổi trong vòng 6 tháng đầu và 6 tháng cuối. Như vậy sự thay đổi này tuân theo phân phối chuẩn 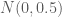
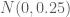
Sự thay đổi trong suốt một quãng thời gian có độ dài T là một phân phối chuẩn 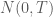
II, Chuyển động Brown
Chúng ta quay lại định nghĩa về mặt toán học của chuyển động Brown. Chuyển động Brown hay quá trình Wiener được ký hiệu là 
 (1)
(1) 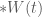

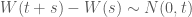

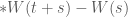
Trong đó ta ký hiệu: 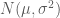
Ta có thể mô phỏng tính chất của chuyển động Brown thông qua đồ thị dưới đây. Trích từ “Mathematical Finance. Theory, Modeling, Implementation” của Christian Fries.

Chúng ta sẽ phân tích một chút về các khái niệm trên:
(1) chỉ mang tính chất chuẩn hoá có nghĩa là để làm đơn giản hoá quá trình mà không làm thay đổi tính chất của nó ta chuẩn hoá giá trị ban đầu bằng một hằng số. Thực chất sự chuẩn hoá không phải là một khái niệm mới, trong chương trình THPT thì chuẩn hoá được sử dụng khá nhiều đặc biệt là trong chứng minh bất đẳng thức đối xứng thuần nhất.
(2) thoả mãn tính chất liên tục của chuyển động Brown, trong quá trình liên tục thì đòi hỏi
(3) là một ứng dụng của định lý Giới hạn trung tâm (The Central Limit Theorem). Hiểu đơn giản thì định lý này có nghĩa là tổng của nhiều biến ngẫu nhiên có cùng một phân phối sẽ là một phân phối chuẩn ngay cả khi các biến độc lập trong đó không phải là phân phối chuẩn. Nhắc lại định lý này như sau:
Định lý giới hạn trung tâm
Cho 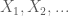
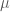
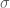

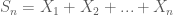
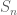

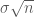
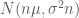
Đây cũng là một trong những định lý quan trọng bậc nhất của xác suất được áp dụng nhiều trong lĩnh vực tài chính. Ta quay lại với (3). Ý tưởng này xuất phát từ việc chuyển động của biến ngẫu nhiên trong khoảng thời gian từ 
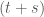

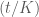
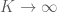
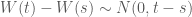
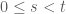
(4) Tính chất này tương tự quá trình Markov đã nói ở phần 1. Các bước chuyển động trong tương lai không phụ thuộc vào những gì đã xảy ra trong quá khứ.
Ở phần trên chúng ta sử dụng tên gọi “quá trình Wiener” thay vì sử dụng tên gọi “chuyển động Brown”. Tại sao lại có sự thay đổi này. Thực chất trong nhiều tài liệu thì định nghĩa một quá trình Wiener có
Định lý đó như sau: “mọi quá trình Wiener 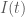
Quá trình Wiener thích hợp để mô tả sự thay đổi có tính liên tục của các biến ngẫu nhiên cơ sở như
Sau đây chúng ta minh hoạ bằng một ví dụ đơn giản sau:
Ví dụ 1: Chọn một biến ngẫu nhiên có phân phối chuẩn 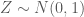
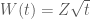
Câu trả lời là không. Mặc dù 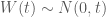
*
* 
* Tuy nhiên: 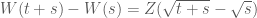

Vậy đây không phải là một quá trình Wiener.
Ví dụ 2:
Cho 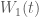

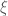

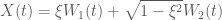
Tiếp theo chúng ta đến với định nghĩa chuyển động hình học Brown, vi phân của chuyển động Brown, quá trình Wiener tổng quát. Sau đó chúng ta sẽ nói về một ví dụ ứng dụng đơn giản liên quan tới quá trình Wiener trong biến động giá chứng khoán.(đang bổ sung)
III, Mô phỏng chuyển động Brown
Ở trên các bạn đã có dịp làm quen với các khái niệm liên quan tới chuyển động Brown tuy nhiên vẫn chưa hình dung ra cách giả lập các mô hình tài chính dựa trên lý thuyết như thế nào. Phần này sẽ giúp các bạn có một cái nhìn tổng quan về việc thiết lập mô hình. Dưới đây là ví dụ thực hành rất cơ bản bằng phần mềm Excel trong việc giả lập chuyện động của giá chứng khoán dựa trên chuyển động Brown, chú ý đây chỉ là một ví dụ đơn giản và không có nghĩa là ta luôn sử dụng mô phỏng này (có nghĩa còn nhiều mô phỏng phức tạp hơn):
http://www.youtube.com/watch?v=oOnD_S2jq4U
Ngoài ra với phần mềm MATLAB ta có thể mô phỏng bằng cách code mã lệnh sau:

Chạy code lệnh cho ra kết quả là đồ thị mô phỏng của chuyển động Brown.

Tài liệu tham khảo:
- Options, Futures and other Derivatives – John C.Hull 7th Edition.
- Mathematical Finance – Vol 2 – PhD. Bùi Phúc Trung.
- Elementary Calculus of Financial Mathematics – A. J. Roberts
- The Concepts and Practice of Mathematical Finance – 2nd Edition – Mark S. Joshi
- Paul Wilmott on Quantitative Finance – 2nd Edition
Bài viết đang trong quá trình hoàn thiện và sẽ được bổ sung trong thời gian sớm nhất có thể…
Sự biến đổi lãi suất
 Tiếp tục với loạt bài liên quan tới nhập môn Toán tài chính hôm nay chúng ta sẽ nói về sự biến đổi của lãi suất. Thông thường lãi suất được sử dụng trong các phân tích tài chính cổ điển đó là giả định rằng lãi suất là cố định trong suốt 1 quãng thời gian, ví dụ điển hình như các mô hình chiết khấu dòng tiền DCF (discounting cash flows) hay Gordon…điều này trong thực tế hầu như không chính xác !?!
Tiếp tục với loạt bài liên quan tới nhập môn Toán tài chính hôm nay chúng ta sẽ nói về sự biến đổi của lãi suất. Thông thường lãi suất được sử dụng trong các phân tích tài chính cổ điển đó là giả định rằng lãi suất là cố định trong suốt 1 quãng thời gian, ví dụ điển hình như các mô hình chiết khấu dòng tiền DCF (discounting cash flows) hay Gordon…điều này trong thực tế hầu như không chính xác !?!
Để tiếp cận với việc mô hình hoá quá trình lãi suất thì trước tiên ta phải tiếp cận các kiến thức cơ bản liên quan đến giải tích mà cụ thể là đạo hàm, tích phân, vi phân… Nhắc lại 1 lý thuyết rất cơ bản và quan trọng của giải tích đó là:
Ý nghĩa hình học của khái niệm đạo hàm là ở chỗ nó biểu diễn tốc độ biến thiên của hàm số thông qua hệ số góc của tiếp tuyếnvới đồ thị biểu diễn hàm số. Về vật lý, đạo hàm biểu diễn vận tốctức thời của một chất điểm chuyển động với vận tốc không cố định.
Như vậy cách tiếp cận liên quan đến sự biến đổi của lãi suất thông qua các phép toán giải tích là điều hoàn toàn tự nhiên.
Trong bài viết này chúng ta sẽ làm quen với biến động liên tục của lãi suất (Continously Varying Interest Rates) cùng với đó là 1 vài công thức biểu diễn giá trị tiền tệ dựa vào tốc độ tăng của lãi suất.
Gọi mốc thời gian hiện tại là mốc 0 và ký hiệu 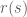

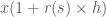
Đại lượng
Gọi 
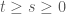

Khai triển và biến đổi ta có:


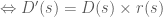
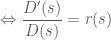
Đây thực chất là phép biến đổi của đạo hàm, tức là:

Từ đó ta lấy tích phân từ 0 đến t của cả 2 vế để tìm mối quan hệ giữa D(t) và r(s).

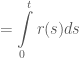

Ta lại có giả thiết 

Trong đó ta ký hiệu hàm exp là hàm mũ:

Hoàn toàn tương tự ta có công thức tổng quát hơn cho 2 mốc thời gian bất kỳ với quá trình biến đổi của lãi suất là 1 quá trình được mô hình hoá.
Gọi 
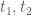



Điều đó có nghĩa là ta có thể biểu diễn giá trị tương lai của 2 giá trị tại 2 mốc thời điểm bằng việc chuyển qua tích phân và hàm tốc độ biến đổi của lãi. Vấn đề là làm sao để xác định được tốc độ thay đổi của lãi?
Giả sử một ví dụ rất đơn giản sau:
Tại năm thứ 2 ta đang có 1 khoản tiền là $10, tính giá trị tương lai của khoản tiền đó tại năm thứ 5 nếu biết tốc độ tăng của lãi theo thời gian 

Như vậy là ta đã thấy được cách tiếp cận bằng giải tích để biểu diễn giá trị của tiền tệ theo thời gian. Một trong những yếu tố quan trọng trong phương pháp này đó là làm sao mô hình hoá được quá trình lãi suất. Vấn đề này sẽ được bàn tới trong các bài viết tiếp theo.
Nhân tử chiết khấu
Trong các bài toán tài chính cơ bản mà cụ thể là bài toán chiết khấu dòng tiền trong tài chính thì công thức sau được sử dụng rất thường xuyên:
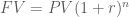
Đây chính là công thức cơ bản giải thích cho khái niệm “một số tiền ngày hôm nay và cùng một số tiền đó nhưng trong một thời điểm khác thì chúng có giá trị không giống nhau”. Nguyên nhân là do các biến động liên quan đến lãi suất, lạm phát,… Trong bài viết này ta giả định rằng lãi suất trong quãng thời gian là như nhau (điều này để làm đơn giản quá trình tính toán) dù thực chất lãi suất là 1 quá trình biến đổi ngẫu nhiên không cố định mà chúng ta sẽ đề cập ở các bài viết sau.
Đối với toán tài chính thì công thức này vẫn được sử dụng rất phổ biến. Tuy nhiên khi tìm hiểu sâu về toán tài chính thì người ta ít sử dụng nhân tử 

Giả sử lãi suất r% /năm, số kỳ ghép lãi trong năm là m lần khi đó nhân tử chiết khấu (sau 1 năm) sẽ là đại lượng:

Ta giả định rằng số kỳ ghép lãi trong năm m dần tiến dần về vô cực. Mặt khác lại có:

Ta xấp xỉ :
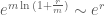
Đây thực chất là hệ quả từ khai triển Taylor của hàm số 

Bỏ qua sự phức tạp của đạo hàm chúng ta có một hướng chứng minh khác là dùng định lý l’Hopitals Rule. Xem lại định lý này ở đây. Thực chất ý nghĩa của định lý này là khi ta tính giới hạn của các dạng vô định như 0/0, vô cùng/vô cùng thì ta sẽ lấy đạo hàm để khử vô định.
Ta cần tính: 
Đặt 


Đây là dạng tìm giới hạn vô định 0/0 để khử vô định ta lấy đạo hàm của cả tử và mẫu:


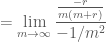


Như vậy ta có thể kết luận khi số kỳ ghép lãi trong năm là một số m tiến đề dương vô cùng thì khi đó sau t năm ta có:

Ngược lại khi ta muốn tính hiện giá của dòng tiền, giả sử ta có FV tại thời điểm T thì giá trị PV tại thời điểm t (t<T) được tính như sau:

Trong các bài viết tiếp theo chúng ta sẽ tiếp tục tìm hiểu các khái niệm cũng như ký hiệu cơ bản được sử dụng trong nhập môn Toán Tài Chính. Các công cụ toán được sử dụng trong Toán tài chính tưởng chừng như rất phức tạp nhưng thực chất vẫn dựa trên các khái niệm cơ bản sau (trích Paul Wilmott – 1 trong những chuyên gia hàng đầu về Tài chính định lượng ở Mỹ):
+ Số e
+ Log – Ln
+ Kỳ vọng (expectation)
+ Khai triển Taylor – Chuỗi Taylor
“What mathematics have we seen so far? To get to (1.2) all we needed to know about are the two functions e (or exp) and log, and Taylor series. Believe it or not, you can appreciate almost all finance theory by knowing these three things together with ‘expectations’. I’m going to build up to the basic Black–Scholes and derivatives theory assuming that you know all four of these. Don’t worry if you don’t know about these things yet, take a look at Appendix A where I review these requisites and show how to interpret finance theory and practice in terms of the most elementary mathematics. Just because you can understand derivatives theory in terms of basic math doesn’t mean that you should. I hope that there’s enough in the book to please the Ph.D.s1 as well.”
Khai triển Taylor có thể tìm đọc ở đây.
http://vi.wikipedia.org/wiki/%C4%90%E1%BB%8Bnh_l%C3%AD_Taylor
Định lý l’Hopitals Rule
http://vi.wikipedia.org/wiki/Quy_t%E1%BA%AFc_l%27H%C3%B4pital
